As July came to an end, so did my 6 months at STAR Labs. I started a three-month internship at the Singapore-based vulnerability research firm in February, before deciding to extend my time there until August. Going in, my goals were simple: to experience life as a vulnerability researcher (and see if it suited me), and to find a single Linux kernel zero-day (for the #streetcred). Coming out of the internship, I’m thankful to have achieved these goals and more.
Since blog posts talking about the ‘behind-the-scenes’ of vulnerability research (VR) are few compared to technical analyses, I thought I’d write this post to pull back the curtain of what the work is like. In this post, I’ll share my experiences racing in Google’s KernelCTF, competing at Pwn2Own, and what I learned along the way.
 The anatomy of a bug (Piotr Jaworski/Creative Commons)
The anatomy of a bug (Piotr Jaworski/Creative Commons)
KernelCTF
To the uninitiated, KernelCTF is Google’s kernel bug bounty program; the CTF name is a bit of a misnomer. In a nutshell, if you find a bug in the kernel and demonstrate its exploitability on Google’s kernel instances by achieving local privilege escalation, you are eligible for a bug bounty.
After joining STAR Labs, my first task was to analyze Linux Kernel n-days. One of the bugs I analyzed was in the Linux kernel’s network scheduler subsystem, or net/sched for short. This was a bug that had been recently exploited in KernelCTF, and I was tasked with writing an exploit based only on the bug’s patch.
Coincidentally, a few days into my analysis, h0mbre published an amazing blog post detailing his exploit for the very bug I was analyzing; he had the same idea of reviewing recent KernelCTF entries. Anyway, there was little point in continuing work on that n-day after reading his blog post. Given that there had been a few net/sched bug reports recently, my mentor, Ramdhan, suggested I look for variants of those bugs.
After a few days, I found what looked like a potential bug. It looked like a variant of a previously reported bug. However, the bug I found would only be triggered under very specific conditions. In order to verify that it was actually a bug, I ran a debug version of the kernel with those conditions always set to be true. When I sent my test payload, I was psyched to see that the bug was indeed valid — I managed to obtain a use-after-free. I quickly set out to figure out how to actually satisfy those conditions, but no dice. I roped in my mentor, but after a few days, we still could not satisfy the last required condition. At this point, I made the tough decision to give it up and move on.
A few days later, that decision paid off as I found my first bug in a separate part of the subsystem. Excitedly, I cobbled together an exploit, building upon ideas in h0mbre’s blog post. That day, I wolfed down my lunch, rushing back to my desk to put the finishing touches on my exploit script. After a few runs of debugging the remote environment, the exploit worked! I had successfully exploited a KernelCTF instance.
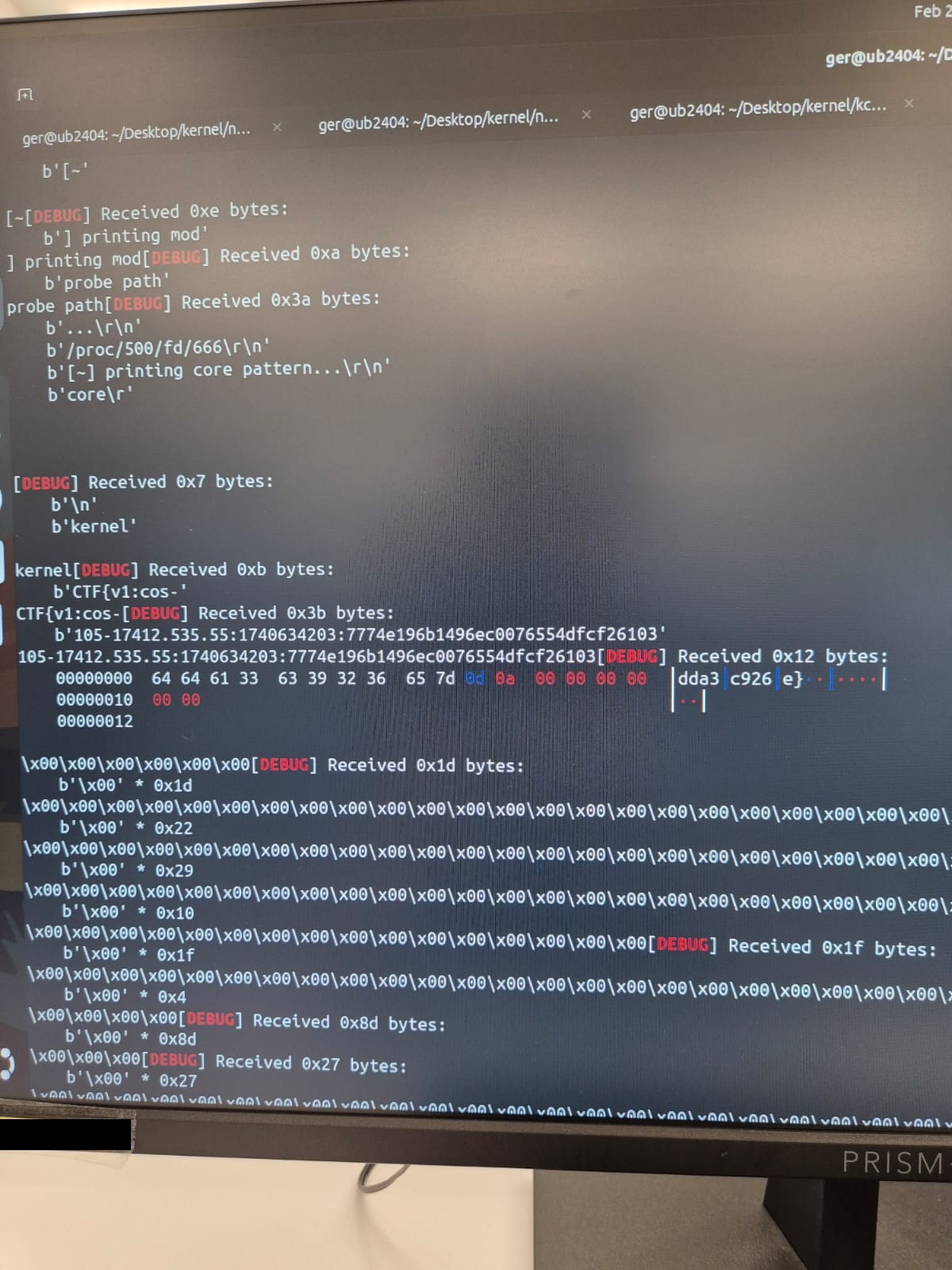 The flag is in the format
The flag is in the format kernelCTF{xxx}
That first flag was the start of an exhilarating 2-3 months, as I would continue bug-hunting for KernelCTF.
The race is on
Now’s a good time to explain how KernelCTF works. KernelCTF has 3 target instances: LTS, COS, and Mitigation, each running a different version of the Linux kernel. Pwning the LTS instance rewards the highest bounty. To avoid a surplus of bug submissions, the program only accepts one new entry every 2 weeks. When a new LTS and COS instance with a more recent version of their respective kernels is released, researchers only have a single window to pwn it. The reward goes to only the first researcher to pwn the instance successfully, while the other researchers have to wait 2 weeks to try again. The KernelCTF team publicizes details about the new instance in advance, so researchers can prepare their exploits before the instance is released. At the moment the instance is released (Friday 12:00 PM UTC), there will usually be 3-4 researchers racing to connect to the lucrative LTS instance (paying up to $70k USD for a single bug!) and run their exploits. This is the so-called KernelCTF “race”. It is possible to lose the race for multiple consecutive windows, leading to some researchers hoarding their zero-days until they win a race.
With that first zero-day I exploited on COS, I adapted it to work for the LTS and Mitigation instances as well. I was ready to compete in my first race.
Here’s what the submission process normally looks like: the researcher SSHes into the instance, solves a proof-of-work, uploads their exploit files, runs the exploit, gets the flag and enters it into a Google Form to complete their submission. The first researcher to submit the Google Form (based on the form response’s timestamp) wins the race.
Eager to win the race, I decided that my best chance at being the fastest was to automate the entire process from start to finish. This isn’t a new idea; some researchers have publicly talked about using automation to win the race. So, I had to put extra thought into optimizing my pipeline. With a week before the next LTS release, I sunk my time into building a pipeline to automatically connect to the instance, download the exploit and run it, and submit the flag.
After all my work — finding a zero-day, writing an exploit and creating an auto-submitter — all I could do was wait. When the time for the new release came around, I was in the office, my eyes glued to the interface of the auto-submitter.
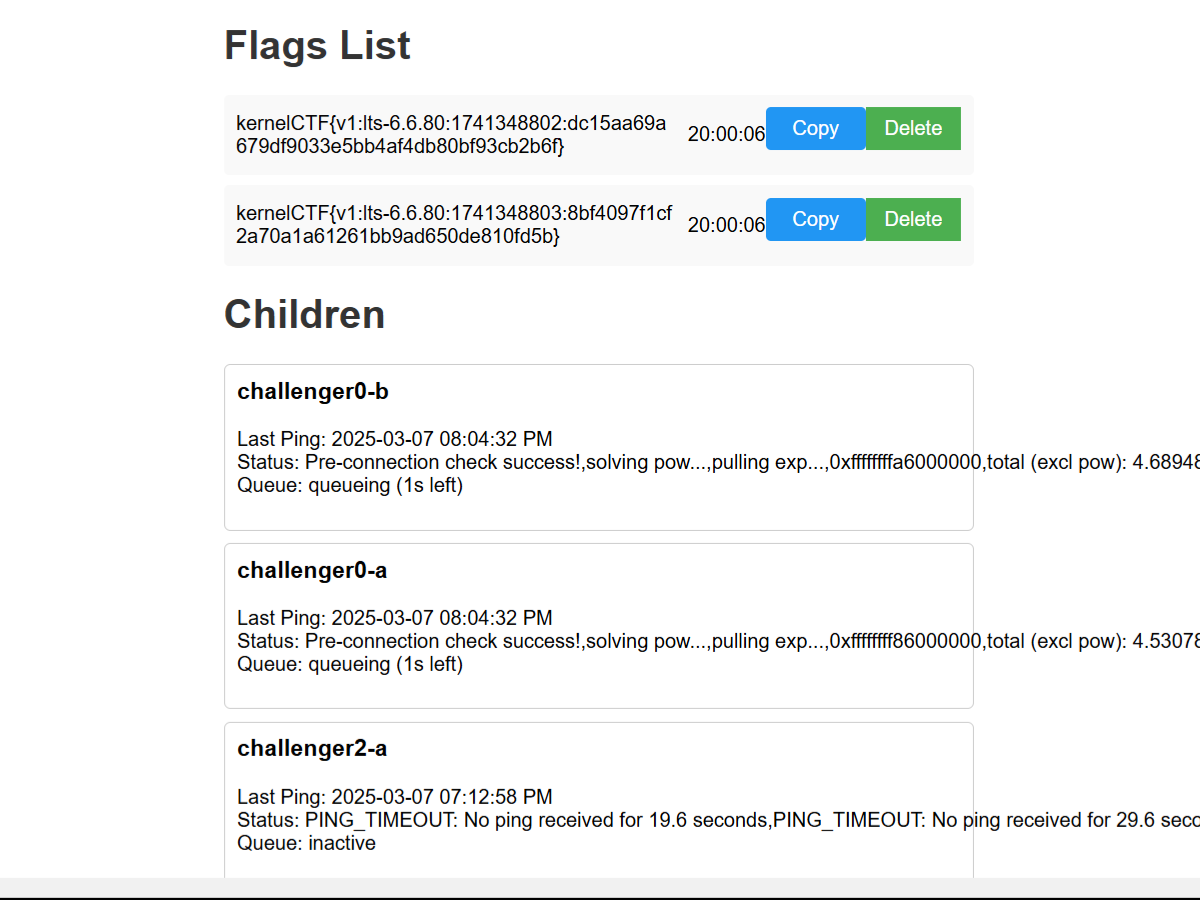 The web interface of the auto-submitter
The web interface of the auto-submitter
Great! The auto-submitter captured the LTS flag and submitted it. But it was too early to celebrate — was I the first? Nervously, I opened up the public Excel sheet to check if anyone had been faster in submitting the flag…
 My first zero-day that pwned all 3 KernelCTF instances: COS, LTS and Mitigation. I won the LTS race by performing the LPE and submitting the flag 10.97s after the instance was released.
My first zero-day that pwned all 3 KernelCTF instances: COS, LTS and Mitigation. I won the LTS race by performing the LPE and submitting the flag 10.97s after the instance was released.
Success!
If you are interested in reading more about optimizing the submission process, the Crusaders of Rust have an incredible blog post about beating the proof-of-work.
Off to the races
Another element of the KernelCTF race is that only the first submission for a bug counts. If one researcher exploited a bug in the previous LTS instance 2 weeks ago and another researcher exploits the same bug in the latest LTS release, only the first researcher receives the bounty. Unfortunately, there is no way of knowing if somebody else has discovered the same bug until details of their submission are public. Depending on how long it takes the kernel maintainers to fix the bug, this can take upwards of a month. This means that for targets that many researchers are looking at, there is pressure to find bugs as quickly as possible, before other researchers find them too.
With the release of h0mbre’s post, research into net/sched was heating up. With more eyes on the subsystem than there had ever been, I was keen to preserve my momentum from that first bug. This began a frenzy of research as I pored over the codebase night and day. I wish I had more interesting anecdotes to share about the code audit process, but as you can imagine, it was just a lot of reading and debugging kernel code.
I’m working on a separate post for the STAR Labs blog containing a technical analysis of the subsystem, including a discussion of the bugs I found. There’s a lot of interesting details to cover, more than I can fit into this post!
This period was marked by a single goal: speed. Finding bugs fast; hyper-optimizing my exploit so that it ran as quickly as possible, sacrificing reliability if need be; minimizing latency in my auto-submission pipeline. Those weeks were thrilling, as I was always pushing myself to find new bugs and to improve the process. By the end of my internship, I had successfully submitted four zero-days. Each of the first three bugs targeted all 3 KernelCTF instances, while the last bug targeted only COS and Mitigation. All four bugs are now patched upstream!
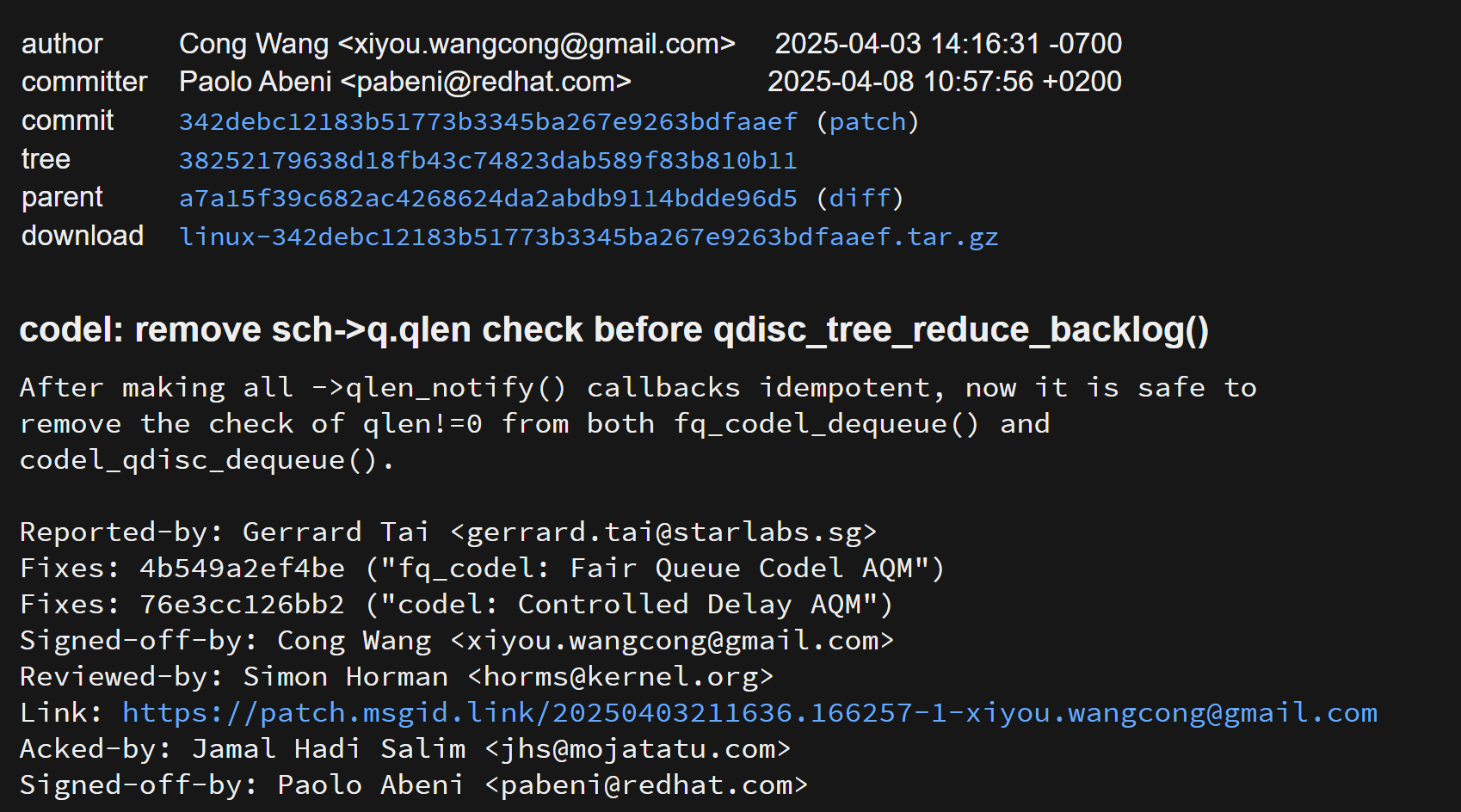 My first contribution to the Linux kernel.
My first contribution to the Linux kernel.
As part of the KernelCTF guidelines, I had to report the bugs to the kernel maintainers as well. For net/sched, this involved a fair bit of correspondence on the private security@kernel.org channel and the public netdev mailing list. For the first time, I was interacting with kernel maintainers as I discussed fixes with the original authors of the vulnerable components. While most of these correspondences were pleasant, some maintainers seemed a bit annoyed. Having done my fair share of software development over the years, I can empathize with them — I was using the system in unintended ways and then complaining that it broke. Normally, developers would prioritize features and reports related to actual use cases, so they should consider this a low-priority report. However, given the security implications of the bugs I was reporting, they had to prioritize the report and consequently push back the rest of their work. For many developers, their passion would be in working on the subsystem and providing utility for its many users. Unfortunately, the fact that the subsystem is in the Linux kernel meant that they now had the added obligation to care about the kernel’s security model. Indeed, if I were a developer receiving these security bug reports, I would probably see it as a chore to fix them. All in all, this disclosure process has given me a newfound respect for kernel maintainers.
Pwn2Own
Other than KernelCTF, the other highlight of my time at STAR Labs was competing at Pwn2Own. After finding some success in KernelCTF, my boss proposed I work on the Linux operating systems target for Pwn2Own. This year, the Linux OS target was Red Hat Enterprise Linux (RHEL). In order to secure a win in that category, I had to demonstrate a Local Privilege Escalation on an up-to-date RHEL desktop environment. The Pwn2Own rules also requires competitors to use zero-days in their exploits; one-day exploits don’t count as full wins.
I was excited to start work on RHEL. Joining Pwn2Own had always been a distant dream of mine, but I was now actually in a position to do so. Although RHEL also uses the upstream Linux kernel, it has a somewhat different kernel configuration from the KernelCTF instances — certain kernel features were not compiled in but others were. Ultimately, this required me to look elsewhere for bugs.
Going from working on KernelCTF to Pwn2Own, my priorities shifted as well. In Pwn2Own, you only get three attempts at pwning your target. Running your exploit script once counts as one attempt. So, if the exploit is probabilistic, you want your script to automatically retry the exploit until it works. In addition, if your exploit fails and crashes the system, your attempt is over. This forced me to focus on reliability and minimizing side-effects, which had not been a priority in KernelCTF. In a way, this is closer to a real-world exploitation scenario.
Part of the ‘realism’ is that the target machines aren’t available to you until the competition day. While we were informed of the laptops’ general specifications, we could not actually interact with them. To avoid unexpected configurations, I had to rewrite my exploit to be more robust — considering common configuration possibilities and avoiding assumptions about default values.
The final part of the ‘realism’ is the last-minute vendor updates. The organizers lock the versions of the targets only a few days before the competition. If a vendor releases an update before the version lock, that new version is considered the up-to-date version, and competitors must adapt their exploits to work on it. This has made for unfortunate situations in the past, where participants got off their flights only to discover that the latest version had patched their bug. When I saw that RHEL had indeed released a new kernel version, I scrambled to read the new source code. Thankfully, my bug had remained unpatched, and my exploit worked again after updating the offsets of kernel structures.
Welcome to Berlin
This year, the competition was held alongside OffensiveCon in Berlin. There, I met up with Thach, my colleague. The two of us would represent STAR Labs at the competition. As a company, we had entries across 6 different targets: Windows 11, Docker Desktop, VMware ESXi, RHEL, VirtualBox, and NVIDIA Triton Inference Server. Thach was targeting ESXi, and I was targeting RHEL; the other entries were our colleagues’ work. Since they could not attend the conference in person, Thach and I would run their entries for them.
 The famous Checkpoint Charlie in Berlin.
The famous Checkpoint Charlie in Berlin.
I was tasked with running the Windows 11 LPE and Docker Desktop container escape on the first day of the competition. I was terribly nervous about accidentally messing up my colleagues’ attempts. Pwn2Own was the culmination of many weeks of effort, and I’d hate for their work to go to waste because of mistakes on my part. Before the competition, I rehearsed their exploit steps in my hotel room until I was confident. Thankfully, the steps were straightforward, and their exploits worked without a hitch during the competition. This ‘stage experience’ helped ease my nerves for when I had to run my entry on the second day.
While I was only running those two entries on the first day, there were plenty of other attempts going on, including two teams targeting RHEL. Before the competition, the organizers randomly chose the sequence of attempts; I was drawn last to perform my attempt. This is unfortunate because of the competition’s bug collision penalty — if two competitors find and exploit the same zero-day, the one who performs their attempt first receives the full score while the second one receives no score. While the Linux kernel offers a huge attack surface and teams usually won’t face bug collisions, this slim possibility remained at the back of my mind throughout the first day of competition.
After a smooth first day, I was hoping for similar success on the second day. After lunch, I tested my RHEL exploit a few more times to make sure everything was working before heading to the competition room. There, the staff seated me at the contest table, where the target laptop running RHEL awaited, and handed me a brand-new flash drive. I unwrapped the packaging and transferred my exploit onto the flash drive, which they then transferred onto the laptop. When my allocated time slot came around, the cameras started rolling (the whole competition was livestreamed!) and a small crowd began gathering around the table. The staff member assigned to me asked if I was ready to run my exploit. After giving him my confirmation, I watched as the exploit logs started filling the console: configuration settings, leaked addresses, confirmation of obtained primitives.
Everything was going according to plan. Until… it wasn’t.
The final step in the exploitation had failed. Normally, this would not be an issue; my exploit code was programmed to retry the step until it succeeded. But this time, the retry count kept climbing. Twenty retries. Fifty. By the time the retry count had hit one hundred, I was beginning to entertain the possibility that this attempt would not succeed. In all my tests, this step had always succeeded within a few retries.
Remember earlier when I said “To avoid unexpected configurations, I had to rewrite my exploit to be more robust”? I suppose that’s not entirely true because this last step of the exploit was still reliant on a specific configuration (the bug would not work under alternative configurations). Sitting there in front of the live audience, watching the terminal screen, I could only make a best guess as to why the exploit was failing. Unable to interact with the laptop, I had to make a call.
I decided to end my first attempt and start preparing for my second shot. However, I knew that if my hypothesis was right, running the same exploit again would still fail because of the incorrect configuration option. I needed another plan.
Fortunately, I had one. Prior to the competition, my colleague Le Qi had recommended preparing backup exploits in case of last-minute patches or unexpected failures. I had heeded his advice and prepared a backup exploit, using a completely different bug and exploit chain. This backup exploit was one that I was almost 100% confident would work.
I loaded the new exploit onto the flash drive and crossed my fingers going into my second attempt. Despite the tension in the room, I was calm. I was confident in both my triage of the first attempt’s failure and my backup exploit. The staff member ran the new exploit script and…
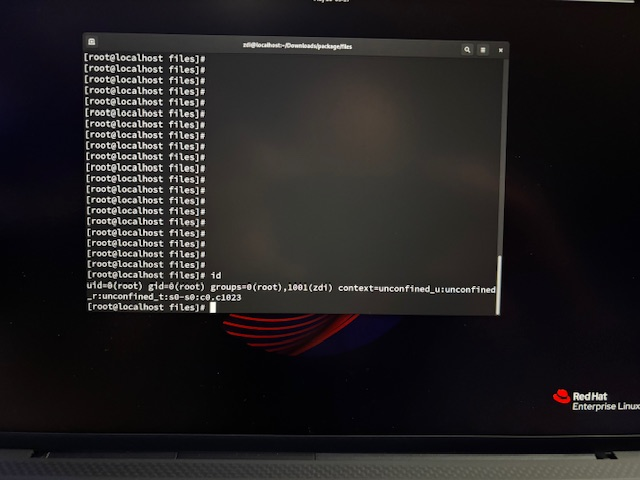 Root shell on the competition laptop
Root shell on the competition laptop
Pwned!
The uncertainties weren’t over yet, though. I still had to get through the disclosure room. This was a private room where participants would discuss the zero-days they used with the organizers. Then, the organizers would check if they had received prior reports for the vulnerability (via their internal database) or if the vendor was aware of it (e.g. through their in-house audit team). In either case, the attempt would be considered a failure. I was slightly worried. I had saved my backup exploit for my second choice because the bug it used was quite shallow — you would not need a deep knowledge of the subsystem to spot it — so there was a higher chance that it had been reported before. Luckily, my worries were all for nothing when the disclosure team confirmed it was a novel vulnerability; I could finally celebrate!
Goodbye, Berlin
It was awesome meeting everyone at OffensiveCon. I could finally put a face to some Twitter handles. The afterparties on both days were fantastic too — I met tons of interesting people there!
Incredibly, STAR Labs topped the leaderboard after 3 days of competition, bringing home the coveted Master of Pwn title. A few months ago, I was watching Pwn2Own from afar, wondering if I’d ever get the chance to take part. Now, I was standing on stage, lifting the Master of Pwn trophy. The credit belongs mostly to my teammates — they tackled the hardest targets — but the experience showed me that what once felt out of reach was closer than I thought. It was a privilege to work alongside such talented teammates, and the experience reminded me how much I still have to learn.
 Thach and I receiving the trophy on the OffensiveCon stage
Thach and I receiving the trophy on the OffensiveCon stage
Greetz
This whole journey has been a wild ride. All things considered, I’m pretty happy with what I managed to achieve. This has already turned into quite a long “Dear diary,” so I’ll wrap it up by talking about the people.
Shout-out to all the write-up authors. I will forever be grateful for the countless CTF and VR write-ups that people upload. They are an invaluable resource to the community, lowering the barrier to entry for all who are interested.
Thank you to the STAR Labs staff, who were friendly and helpful during my time there. In particular, my mentor, Ramdhan, who was always willing to lend a hand, and my boss, Jacob, for supporting my endeavors. And of course, the other interns who made the office warmer on those occasional rainy days.
During my internship, one question I had on my mind was, “What kind of people stick around in VR?”. In those 6 months, I had the opportunity to talk to many people within the community and learn about their perspectives. I’ll put these takeaways about the bug-hunting process in a separate post.